Protein sequences can be determined directly or from the DNA that encodes them. The sequence of amino acids in a protein determines its biological function. Direct determination of the amino acid sequence of an unknown protein is accomplished first by cutting the protein into smaller peptides at specific residues. For example, cyanogen bromide cleaves proteins after methionine residues, and the enzyme trypsin preferentially cleaves proteins after lysine and arginine residues. The amino acid sequences of the individual peptides are determined by removing the amino acids one by one through a set of reactions known as Edman degradation. This process leaves the question of how to order the different peptides, a step usually accomplished by comparing the sequences of the individual peptides arising from different cleavage steps.
The direct determination of an amino acid sequence is a very tedious process. Most protein sequences are now determined by determining the DNA sequence of the gene that encodes them; the amino terminus of a protein is the only portion that is determined directly. The sequence of DNA is then converted to the corresponding predicted protein sequence by using the genetic code to translate the codons into amino acids.
Amino acid modification. Although determining a DNA sequence is easier than identifying a protein sequence, the information obtained is incomplete and can be misleading. A large variety of functional groups may be added or removed from the side chains of amino acids in the protein. For example, two cysteine residues can be oxidized to form a disulfide bond:
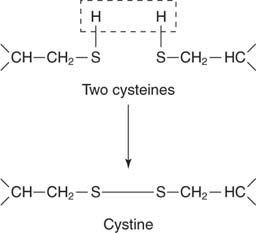
Sometimes the two joined cysteines are called cystine. Disulfide bond formation is an oxidative process; the sulfurs each lose a hydrogen atom, becoming more oxidized. Proteins found outside the cell are more likely to have disulfides than are proteins found inside the cell. This is due to the more reducing environment in the cell. Thus, for example, digestive enzymes found in the small intestine have disulfides, while many enzymes involved in cell metabolism have free (reduced) cysteine –SH groups.
Many other functional groups can be added to proteins post‐ translationally. Sugars or oligosaccharides can be added to the side chain oxygen of serine (O‐linked glycosylation) or to the side chain nitrogen of asparagine (N‐linked glycosylation). Phosphates can be added to the side chain oxygen atoms of serine, threonine, or tyrosine; this process is often important in cellular regulation. Proteins can be covalently bonded to each other. For example, the side chains of the protein collagen (found in skin and connective tissue) are linked together. These cross‐linked residues are important in preserving tissue integrity, and, as humans age, they become more extensive, leading to the well‐known loss of flexibility in old age.